
In colocation data centers, UPS lifecycle TCO risk is rarely created by a single failure event. It emerges when battery replacements, capacitor interventions, and system refresh cycles begin to overlap, compressing redundancy and forcing multiple tenants into shared reduced-protection states at the same time. Conventional UPS architectures often synchronize these interventions by design, particularly when mid-life capacitor replacement cycles align with battery programs and constrained maintenance windows.
This article examines how UPS architecture determines whether lifecycle maintenance becomes a localized operational task or a recurring system-level risk event. It explains why extended capacitor service life, distributed maintenance domains, and architectures that avoid shared operating states can reduce clustered interventions, lower long-term operational disruption, and reshape total cost of ownership over a 30-year facility lifecycle.
Where UPS Lifecycle TCO Risk Starts: When Maintenance Stops Being Isolated
- Redundancy shrinks during “routine” work
- Battery years arrive early
- Capacitors trigger mid-life campaigns
- Building life outlasts UPS life
- Architecture defines blast radius
- The quarter everything becomes “urgent”
UPS lifecycle TCO risk begins when maintenance events stop being independent and start overlapping. The problem is not the intervention itself—it’s the assumption that each intervention remains isolated.
This becomes a commercial risk in colocation data centres, not just an engineering one. When multiple maintenance activities overlap, multiple tenants are exposed to reduced protection at the same time, increasing the probability of SLA-impacting events—even if no outage occurs.
This is where sites discover that “N+1 on paper” becomes “one more fault away” in operation.
A typical scenario: two rooms are already operating under constrained conditions for battery replacement, and a third requires a capacitor intervention that was not forecasted. What follows is not a technical failure—it’s a sequencing problem. Isolation points are shared, bypass paths are no longer local, and commissioning windows begin to stack.
At this point, lifecycle planning turns into risk management under constraint, where every additional intervention increases operational exposure and coordination complexity.
The only way to contain this is by design. If the architecture allows maintenance domains to remain small—through separable connection points, flexible topology, and fault domain separation—interventions can stay local. If not, routine work becomes a hall-wide operating condition, and lifecycle TCO risk escalates by design.
The quarter everything becomes “urgent”
Clustered interventions don’t fail because the work is hard; they fail because the plan assumes interventions stay isolated.
The only way this stays manageable is if the maintenance domain remains small under real conditions: separable connection cabinets, flexible topology, and fault domain separation so one work package doesn’t force a hall-wide operating mode change.
Good lifecycle planning starts with containment. When maintenance domains stay local, redundancy remains available and intervention sequencing stays predictable. Use the white paper to see how distributed architecture supports this operating model.

What triggers clustered maintenance?
| Trigger | Typical cause | Architectural lever |
| Battery campaigns | Aging + risk policy | Phased replacement capability |
| Capacitor replacement | Fixed mid-life interval | Extended capacitor design life |
| System refresh | Design life mismatch | 30-year architecture |
| Maintenance overlap | Shared constraints | Fault domain separation |
Why UPS Design Life Assumptions Create Unexpected TCO Spikes
Planning to nameplate design life creates a specific failure mode: the year nothing was supposed to happen—but everything does.
Components don’t age under brochure conditions. They age under temperature, load profile, harmonics, and real access constraints.
The issue is not that components age—it’s that they age together.
When batteries, capacitors, and control subsystems share aligned design-life assumptions, replacement cycles synchronize by default. The real question is not how long components last, but whether the architecture allows decoupling those cycles.
In practice, risk reviews pull replacements forward to protect SLAs, and scope expands faster than procurement can react. A staged battery plan becomes a bulk intervention event, driven by risk tolerance—not design intent.
Risk-based replacement only works if the architecture supports parallel work without forcing shared operating states.
How Capacitor Replacement Cycles Drive UPS Lifecycle TCO Risk
Most lifecycle models treat “the UPS” as one object. In reality, wear components set the tempo—and the tempo drives disruption.
Capacitors are often the hidden synchronizer of lifecycle risk. In conventional designs, their mid-life replacement aligns with battery programs or emerging constraints, forcing clustered intervention windows—even when operators try to stage work.
This is structural, not accidental.
When capacitor replacement extends toward a ~15-year horizon and is decoupled from other interventions, the synchronization effect is reduced at its source. In practice, this durability is not incidental. Capacitors positioned directly in front of well-channelled cooling airflow, combined with high-grade components and accelerated degradation testing, materially extend service life. Internal accelerated ageing comparisons show significantly slower degradation versus conventional layouts, allowing the maintenance calendar to shift from forced mid-life campaigns to controlled sequencing while preserving redundancy during live operation.
The trigger is usually mundane: a routine inspection identifies drift or thermal stress, and suddenly the job requires isolation steps, testing, and parts that weren’t staged. If isolation forces a broader bypass condition, the “quick fix” becomes a prolonged reduced-protection state.
This is where designs break: early warning only helps if intervention stays local.
Capacitors can quietly set the tempo of lifecycle disruption. When intervention timing is decoupled, the facility gains more control over sequencing, redundancy, and tenant coordination. The white paper explains how architecture keeps lifecycle events from converging into one shared operating state.

Why Battery Replacement Cycles Become a Recurring TCO Multiplier
The TCO risk is not the batteries themselves. It is the maintenance state the architecture forces operators into every time those campaigns occur.
Battery systems installed together typically age together. What begins as a planned replacement program expands into tenant approvals, restricted maintenance windows, switching procedures, commissioning sequences, rollback planning, and temporary operating states.
The larger the intervention window becomes, the more the facility depends on shared operating conditions remaining stable during the work.
This is where architecture determines whether battery replacement stays localized or becomes a site-wide risk multiplier.
Systems that support granular isolation, distributed fault domains, and maintenance without shared bypass dependency allow operators to phase replacement programs over time instead of compressing them into synchronized campaigns.
The result is lower lifecycle TCO, fewer overlapping maintenance constraints, fewer reduced-protection states, and less tenant coordination overhead.
Lifecycle Alignment: The Hidden Driver of UPS TCO Risk
The real constraint is rarely component failure alone. It is replacement-cycle alignment.
When batteries, capacitors, and system refresh horizons converge on the same timeline, operators lose scheduling flexibility and maintenance stops being isolated work.
This is where lifecycle TCO risk accelerates. Not because components fail more often, but because the architecture forces operators into recurring synchronized maintenance states.
Architectures with extended and staggered component lifetimes reduce this coupling at the source. Instead of concentrating risk into a few large intervention periods, they allow maintenance to be distributed over time while preserving operational flexibility.
When UPS Design Life Falls Short of Facility Lifecycle
Even if batteries and capacitors are managed well, the UPS system lifecycle may still be shorter than the facility’s.
This creates capex cliffs and operational risk, where replacement becomes an infrastructure project—not maintenance.
Now the problem is staging: live-space constraints, rollback risk, and operational continuity.
Vendor diversification fails here because interfaces, bypass paths, and control assumptions are not neutral. What looked flexible at procurement becomes rigid during replacement.
Lifecycle impact on cost and risk
| Factor | Conventional UPS | Extended Design Life UPS |
| System design life | ~10–15 years | ~30 years |
| Full replacement | Required (1–2 cycles) | Avoided |
| Capacitor intervention | Mid-life (~7–10 yrs), often aligned | ~15 yrs, removes synchronization trigger |
| Battery replacement | 3–7 yrs typical | Similar but staged |
| Maintenance pattern | Clustered | Decoupled |
| Operational risk | High during campaigns | Distributed over time |
Why Extended Bypass Operation Increases Operational and TCO Risk
In multi-tenant environments, extended bypass states are not neutral—they are shared exposure windows.
The longer the system remains in temporary states, the more human error, switching complexity, and external disturbance risk compound.
This shows up during prolonged change-outs where bypass becomes the operating mode. Protection layers are reduced, and every additional step increases risk of tenant-visible impact.
Distributed decision-making and fault domain separation are what keep a temporary state from becoming a shared exposure window across tenants. But the answer depends on how the maintenance domain was actually defined: by electrical boundaries, by physical access, and by what can be isolated without forcing everyone onto the same path.
Why UPS Lifecycle TCO Risk Is Higher in Colocation Environments
Lifecycle misalignment is amplified in colocation because risk is shared across tenants.
A maintenance state is never local—it affects:
- multiple SLAs
- multiple load profiles
- multiple operational constraints
What is manageable in a single-tenant site becomes exponentially complex in a shared environment.
How UPS Architecture Determines Lifecycle TCO and Maintenance Risk
Scheduling discipline cannot compensate for architectural coupling.
When lifecycle events begin to overlap, the UPS behaves exactly as it was designed: either containing the intervention or expanding it into a shared operating state.
In conventional UPS architectures, maintenance removes capacity in large increments. A “simple” intervention can force broader bypass dependency, reduced redundancy, or tenant-coordinated operating controls because the system remains electrically and logically coupled during maintenance.
This is where lifecycle TCO risk escalates. Not because components fail more often, but because routine interventions repeatedly force the facility into constrained operating states that increase operational overhead, coordination complexity, and SLA exposure.
DARA™ changes this by reducing the size of the maintenance domain itself.
Each module operates as an independent UPS with its own control logic, static bypass, and power conversion path. Combined with extended component lifetimes validated through rigorous testing, the result is both smaller maintenance domains and fewer synchronized lifecycle triggers.
Maintenance therefore remains localized at module level instead of propagating across the frame.
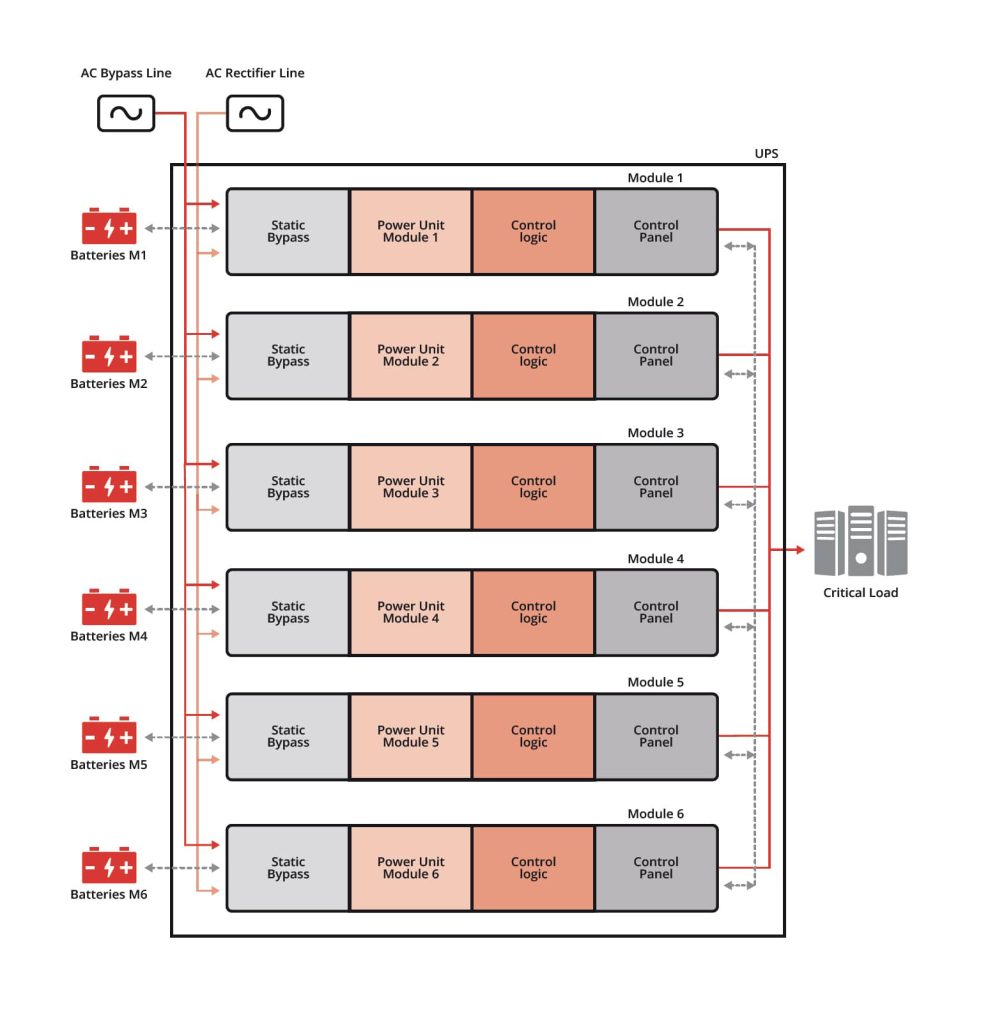
That distinction matters operationally:
- capacitor replacement does not require a system-wide operating mode change
- module intervention does not force healthy modules into bypass dependency
- expansion and restoration can occur incrementally instead of through large synchronized campaigns
- faults remain electrically contained instead of widening across shared infrastructure
This is what separates modular appearance from modular behavior.
A UPS architecture only reduces lifecycle TCO if it allows maintenance, replacement, and expansion to occur without expanding the fault domain during the intervention itself.
Because in colocation environments, the real lifecycle cost is not only the price of replacing components. It is the accumulated operational cost of how often the architecture forces tenants into shared risk states.
Lifecycle TCO improves when routine work stays localized and the fault domain remains contained during intervention. Use the white paper to validate whether the delivered architecture preserves redundancy under real maintenance conditions.

FAQ
Q: Why do UPS replacement cycles in colocation data centers happen earlier than the published design life?
A: Because design life is measured under controlled conditions, while colocation infrastructure operates under real thermal stress, variable loading, harmonics, constrained maintenance windows, and strict SLA requirements. In practice, operators often replace batteries, capacitors, or control components earlier than their published design life to avoid in-service failure risk.
The operational problem is not simply early replacement. It is synchronized replacement. When batteries, capacitors, and system refresh horizons converge, the facility is forced into clustered maintenance campaigns that compress redundancy and expand operational exposure across multiple tenants simultaneously.
Q: Why do capacitor replacement cycles matter so much for UPS lifecycle TCO?
A: Capacitors are one of the hidden drivers of lifecycle disruption because they frequently dictate the timing of mid-life intervention campaigns. In many conventional UPS architectures, capacitor replacement occurs around the same period as battery programs or broader infrastructure refresh planning, creating synchronized maintenance windows.
That synchronization increases lifecycle TCO in ways procurement models rarely capture:
- larger maintenance campaigns
- longer reduced-protection periods
- increased bypass dependency
- more tenant coordination
- higher operational overhead
Architectures that extend capacitor service intervals toward a ~15-year horizon reduce one of the primary triggers for clustered lifecycle events. In designs where capacitors are positioned directly in controlled airflow paths, built from high-grade components, and validated through accelerated degradation testing, service life can be materially extended compared with conventional mid-life replacement assumptions. This reduces synchronization pressure across battery programs and refresh planning, allowing interventions to be distributed instead of compressed into the same operational period.
Q: What is the real operational impact of a 10–15 year UPS lifecycle in a colocation facility?
A: The issue is not only replacement cost. It is what happens operationally when the UPS lifecycle is shorter than the facility lifecycle.
A full UPS refresh in a live colocation environment becomes an infrastructure project involving:
- staged migration planning
- temporary operating states
- elevated operational controls
- rollback procedures
- tenant coordination
- increased reliance on bypass or generators during transition
If the architecture cannot localize maintenance and replacement activity, the refresh itself becomes a multi-tenant risk event.
This is why lifecycle design matters operationally: a UPS architecture intended for ~30-year deployment fundamentally changes how often the facility must enter large-scale intervention states over the life of the building.
Lifecycle TCO risk is not created by components alone. It is created by how architecture defines maintenance domains, replacement synchronization, and fault containment over time.
DARA™ is not only a fault-domain architecture — it is a long-horizon design philosophy. Independent module topology, localized bypass paths, distributed decision-making, and component durability validated through accelerated degradation testing work together to reduce synchronized lifecycle events before they occur.
If you are evaluating UPS architecture for a colocation facility, the question is not only how long components last — it is whether maintenance, replacement, and expansion can occur without expanding the fault domain or forcing shared operating states.
Download the DARA Architecture White Paper for Colocation Facilities Managers to understand:
- how distributed architecture limits lifecycle synchronization
- how maintenance domains are reduced to module level
- how fault containment is preserved during intervention
- and what questions to ask vendors before specifying a system
References
- Data Center Battery Replacement: Zero Downtime Planning Guide — Critical Power Battery Solutions
- How Often Should Data Centers Replace UPS Batteries? A Strategic Approach to Lifecycle Planning
- When Should You Replace an Industrial UPS System in a Data Center? — USA Decommissioning
- UPS for Colocation Data Centers
- Service Overview — UPS Lifecycle Services
This article draws on Centiel’s internal engineering documentation and field experience in colocation power infrastructure.