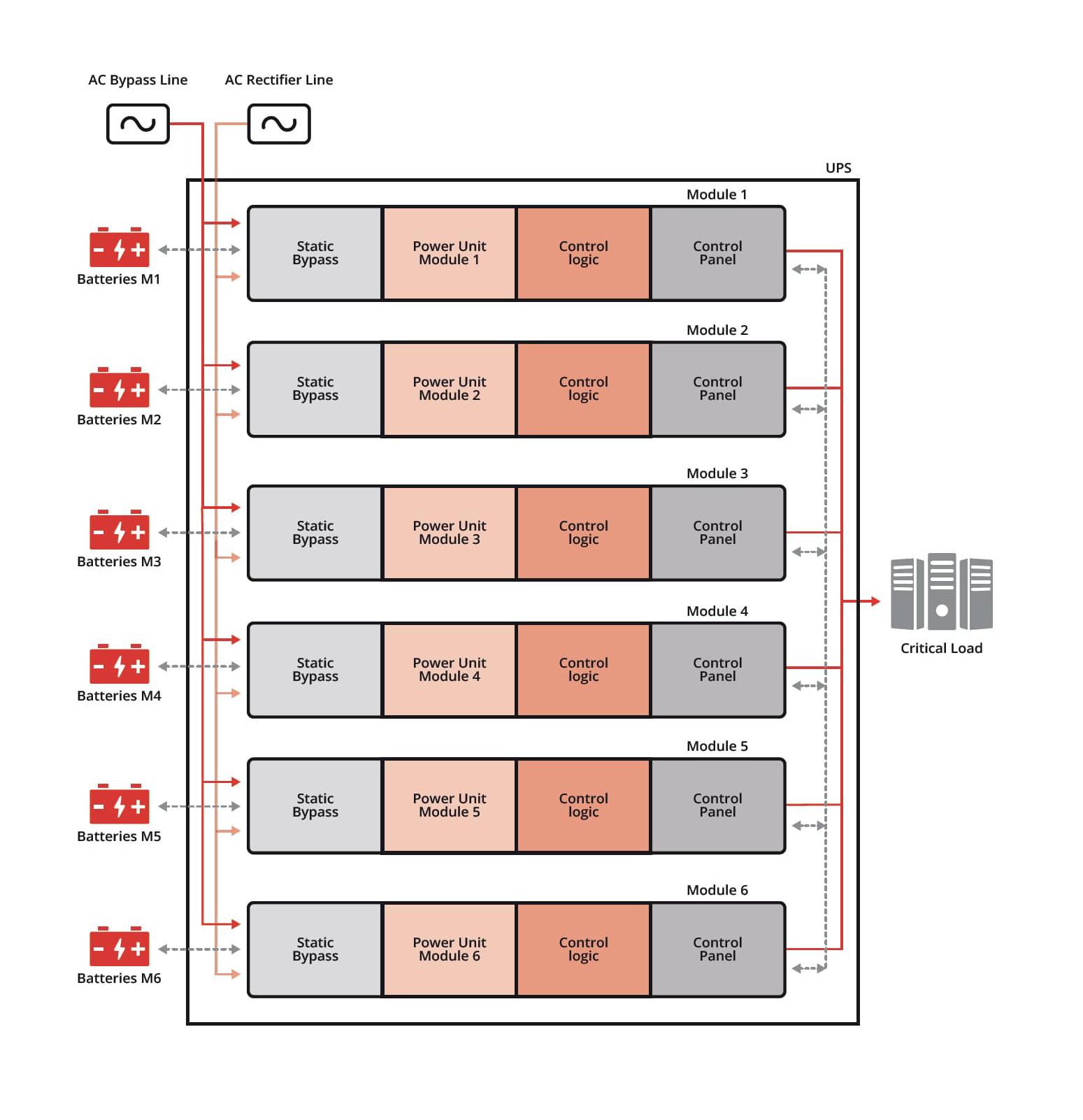
In AI infrastructure, a power failure doesn’t pause the workload. It erases it. The cluster restarts from zero. The financial consequence arrives before the root cause is clear. And the infrastructure leader who approved the architecture is the first person in the room.
At $1M+ per significant outage, the financial consequence arrives before the root cause is identified.
The person who owns the architecture decision owns the outcome. That accountability is the reason this decision deserves the right evidence behind it
The question isn’t whether a power event is possible. It’s whether the architecture was designed so that when the grid fails, the load doesn’t even know.